
AI có thể viết code, giải toán và thậm chí tranh luận như con người, nhưng lại đang “vật lộn” với một thứ tưởng chừng rất cơ bản: file PDF. Đây cũng là lý do không ít người gặp cảnh chatbot tóm tắt sai tài liệu, đọc nhầm bảng biểu hoặc trả lời lệch hoàn toàn nội dung dù đã tải lên đúng file.
Nghe có vẻ khó tin, nhưng PDF thực tế là một trong những định dạng khiến các hệ thống AI hiện đại đau đầu nhất hiện nay.
Thách thức thực tế khi xử lý tệp PDF
Vấn đề này ngày càng lộ rõ khi các cơ quan tại Mỹ công bố hàng triệu trang tài liệu pháp lý dưới dạng PDF trong nhiều vụ việc lớn gần đây. Theo Luke Igel, đồng sáng lập startup AI Kino, việc tìm đúng thông tin trong “núi tài liệu” này gần như là cơn ác mộng, ngay cả khi đã dùng công nghệ OCR để nhận diện chữ viết.
Nguyên nhân nằm ở chỗ PDF vốn không được tạo ra để máy móc dễ đọc hiểu. Mục tiêu ban đầu của định dạng này là giữ nguyên bố cục hiển thị trên mọi thiết bị, đảm bảo tài liệu mở ở đâu cũng giống nhau. Điều đó rất tiện cho con người, nhưng lại trở thành bài toán khó với AI.
Khi đọc một file PDF, AI không chỉ “đọc chữ” đơn thuần mà còn phải tự suy luận đâu là tiêu đề, đâu là ghi chú, đâu là bảng dữ liệu và thứ tự nội dung nên được hiểu như thế nào. Chỉ cần tài liệu có nhiều cột văn bản, biểu đồ hoặc bảng số liệu bị lệch dòng, hệ thống rất dễ hiểu sai hoàn toàn ngữ cảnh.
Đây cũng là lý do nhiều chatbot hiện nay thường hoạt động khá ổn với file Word hoặc văn bản thuần, nhưng bắt đầu trả lời thiếu chính xác khi gặp PDF dài hàng trăm trang có bố cục phức tạp.
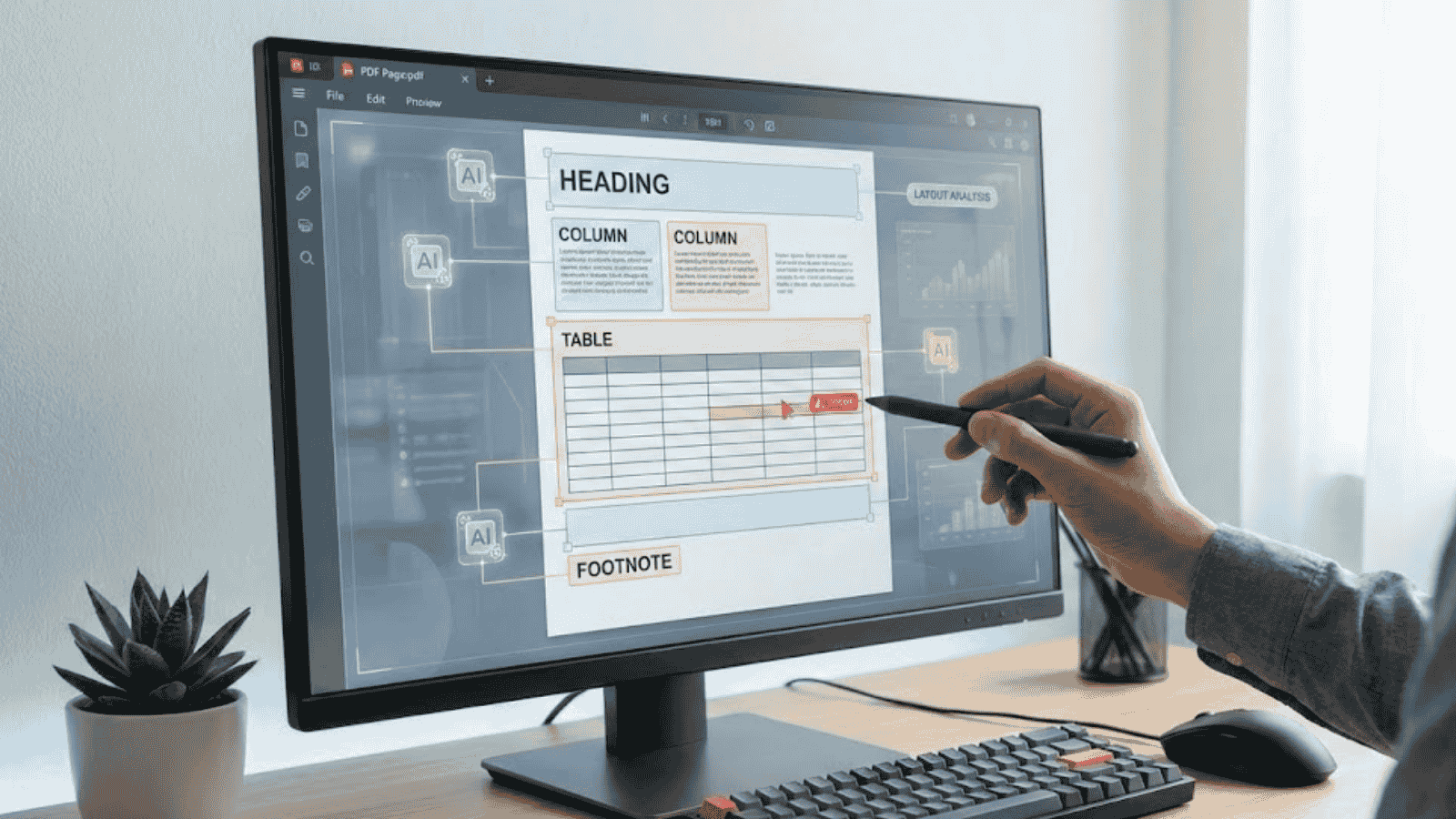
Lý do AI khó hiểu được cấu trúc của PDF
Edwin Chen, CEO công ty dữ liệu Surge, cho rằng khả năng xử lý PDF hiện là một trong những điểm yếu lớn nhất khiến AI chưa thể thực sự trở thành công cụ thay thế con người trong công việc văn phòng và nghiên cứu tài liệu.
Các hãng công nghệ hiện đã bắt đầu cải thiện vấn đề bằng cách huấn luyện AI “nhìn” tài liệu giống như con người nhìn một bức ảnh hoàn chỉnh trước khi đọc chữ bên trong. Thay vì chỉ quét văn bản, mô hình AI mới sẽ cố gắng hiểu cấu trúc tổng thể của trang tài liệu, nhận diện vị trí bảng biểu, sơ đồ và các khối nội dung khác nhau.
Dù vậy, công nghệ hiện tại vẫn chưa đủ hoàn hảo để xử lý ổn định các tài liệu phức tạp như hợp đồng pháp lý, báo cáo tài chính hay hồ sơ nhiều bảng dữ liệu.
Trong lúc chờ AI thông minh hơn, giới chuyên gia khuyến nghị người dùng không nên quá tin tưởng vào việc tải cả một file PDF dài rồi yêu cầu chatbot tóm tắt toàn bộ. Cách an toàn hơn là chia nhỏ từng phần hoặc từng trang để AI xử lý riêng, giúp giảm đáng kể nguy cơ trả lời sai hoặc bỏ sót dữ liệu quan trọng.
Nghe đơn giản, nhưng việc giúp AI “đọc hiểu” PDF thực chất đang là chìa khóa cực lớn cho tương lai của công nghệ này. Bởi phần lớn kho dữ liệu quan trọng của nhân loại suốt hàng chục năm qua — từ tài liệu pháp lý, nghiên cứu khoa học cho tới báo cáo doanh nghiệp — đều đang nằm trong những file PDF mà AI vẫn chưa thật sự hiểu hết.




